SEO and Vue.JS Notes – I recently did some research on this for a new website we’re building. I thought it’s worth a post for future reference and for anyone interested!
Summary
- 90% of what I’ve found suggests you need to use Server-side or pre-rendering Javascript
- Make sure all links are available in the proper a href HTML markup in the “View Source” of page





- Official Google Video
If a website requires JS to show links, then Googlebot has to add an extra element to crawl them – “rendering” is required

JS can be “costly” it needs to be downloaded, parsed and executed

- Official Google Video
“Make sure the content you care about the most, is part of the markup you see in the source of your website”
– All of the homepage meta and all the links in the body render without JS and can be found in the “view source” code
- Official Google Video
Mobile Friendly Test –
Shows the page-rendered source code
If code is missing, or page doesn’t render as expected, check the recommendations
Search Console
https://search.google.com/test/rich-results
“Google can crawl JS….Google may not necessarily fetch all the JS resources”
“Google won’t click or scroll”
“The main content and links won’t be visible to Google”
“The problem is rendering counts towards crawl budget”
– Could be a problem for big eCommerce stores with lots of pages
“Don’t block JS files in robots.txt”
“Problem when websites don’t use traditional ahref links”
Tools
- Disable Javascript
- Onely – what would javascript do – https://www.onely.com/tools/wwjd/
https://developers.google.com/search/docs/crawling-indexing/links-crawlable
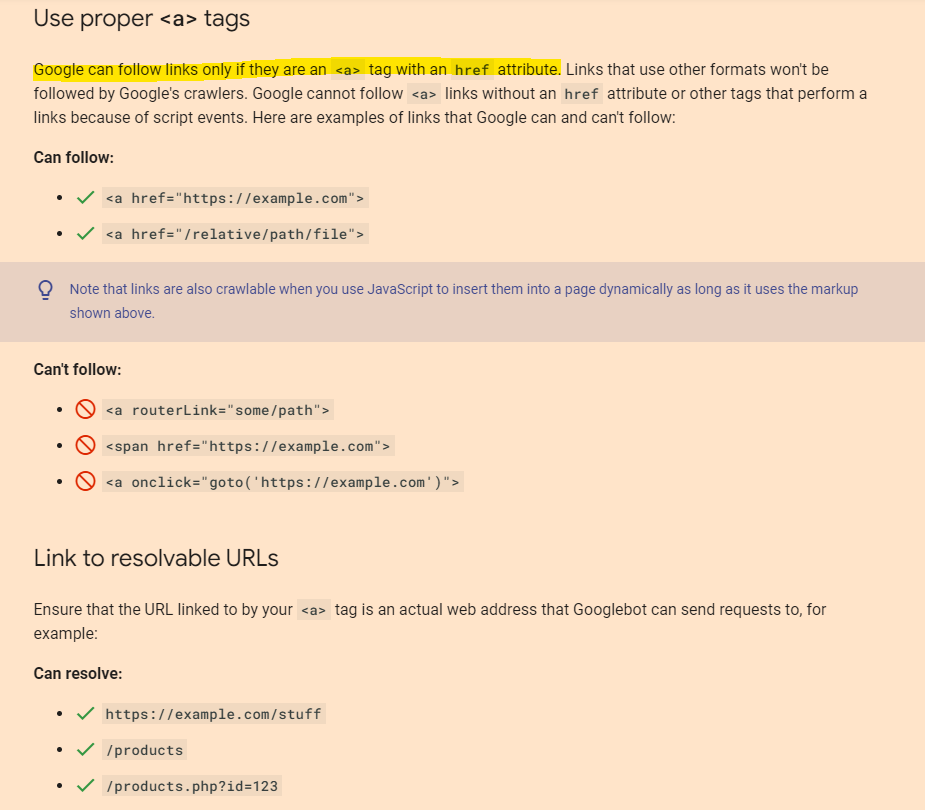
Make your links crawlable
Google can follow your links only if they use proper <a> tags with resolvable URLs:
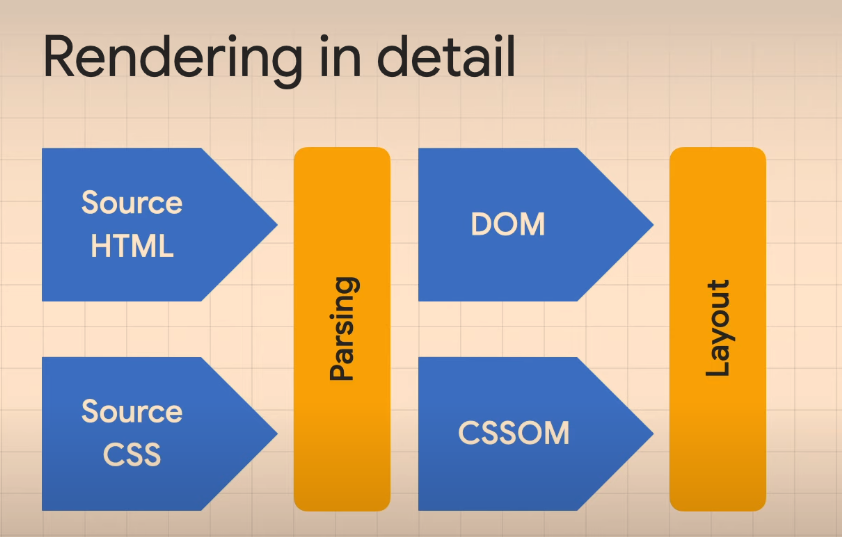
Render tree that creates the sizes, elements etc to display
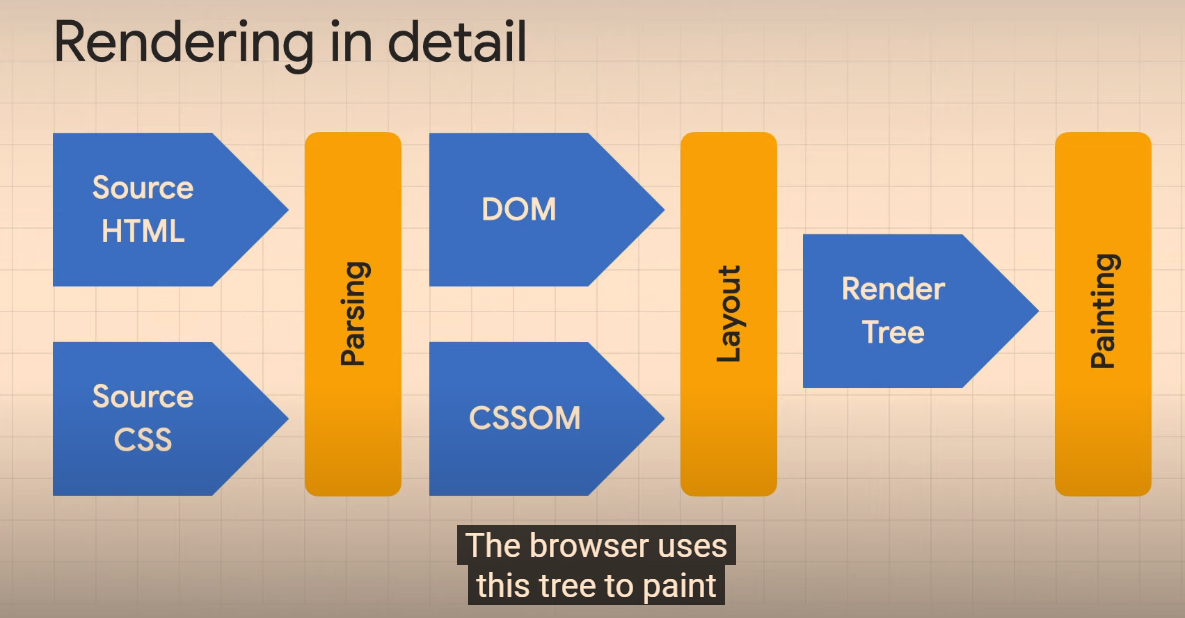
Finally, JS might add, change or remove tree elements – especially when interacting.
“View Source” – shows the Source HTML
Elements Tab in the Developer Tools shows current Dom content, including images etc added by JS
Search Console – Inspect URL – get rendered HTML that Google uses for indexing a page
https://itnext.io/yes-here-are-4-ways-to-handle-seo-with-vue-even-without-node-ssr-719f7d8b02bb
Not everyone can have a Node server for their project. And there may be a lot of reasons for that: shared webhost, no root access…
So here are 4 ways to handle SEO in 2021 with an SPA.
1. SEO on the client side with Google crawlers
React, Vue, Svelte… All these are frontend frameworks initially used to create SPAs, aka websites/webapps with CSR (Client Side Rendering).
What does this mean? It means the rendering is done in the browser. Therefore, the HTML sent to the browser & search engine crawlers is empty!
No HTML content = No SEO.
Remember, you need to handle SEO tags (title, meta…) on the client side! You can use vue-meta or vue-head for that (personally, I prefer vue-meta).
2. SEO with Node-based Server Side Rendering (SSR)
So SSR aka Sever Side Rendering, is a “new” concept that came with frontend frameworks. It’s based on Isomorphic programming which means the same app and code is executed on backend context and frontend context.
Because your app is executed on the backend, the server returns your component tree as an HTML string to the browser.
What does this mean? Since each initial request is done by a Node server that sends HTML, this even works for social media crawlers or any other crawler.
SSR with Vue can be done in 2 ways, DIY or with a framework on top of Vue:
- DIY: https://ssr.vuejs.org
- With Nuxt: https://nuxtjs.org
- With Vapper: https://vapperjs.org
- With Quasar: https://quasar.dev
- With UVue: https://universal-vue.github.io/docs
- With Ream (experimental): https://ream.dev
Of course, SEO with Node-based SSR has it’s drawbacks:
You need… A Node server! Don’t worry, you only need it for the initial HTML rendering, not for your API.
3. SEO using “classic” Server Side Rendering (SSR)
So, based on what we learnt in 1 & 2, we can acheive something similar with a any backend language.
To solve this, we need to do 4 actions with any type of backend:
- Use a backend router that mirrors the frontend router, so that the initial response can render content based on the url asked
- In the backend response, we will only generate title & meta tags since our backend can’t execute frontend code
- We will store some initial data in a variable on the window object so that the SPA can access it at runtime on the client
- On the client, you check if there’s data on the window object. If there is, you have nothing to do. If there isn’t, you do a request to the API server.
That’s pretty much it for the backend, nothing more. You only need a single “view” file that takes title, meta, initialData or whatever parameters you need for SEO/SMO and that’s it.
The “window.initialData = @ json($state)” is also very important here, but not mandatory for SEO. It’s for performance/UX purposes. It’s just for you to have initial data in the frontend, to avoid an initial AJAX request to your API server.
Of course, SEO with classic SSR has it’s drawbacks:
- You have to mirror each route were you need SEO on the backend
- You have to pass “the same data” to the frontend and to APIs, sometimes if feels like duplicating stuff
4. JAMStack aka Static Site Generation aka Prerendering
This is my the method I love the most, but it isn’t meant for all situations.
So what is JAMStack? Well it’s a fancy word for something that existed before that we called: static websites.
So what’s JAMStack then? JavaScript API Markup.
JAMStack is the concept of prerendering, but automated and modernized.
It’s an architecture solely based on the fact that you will prerender markup with initial data, that markup would use JavaScript to bring interaction and eventually more data from APIs (yours and/or others).
In a JAMStack architecture, you would usually use a frontend framework to prerender your static files that would then turn to an SPA.
It’s mostly based on the fact that you would rebuild pages on-the-fly anytime data changes in your APIs, through webhooks with CI/CD.
So it’s really nice, but not great for websites/webapps that have daily updates with a lot of pages.
Why? Because all pages are regenerated each time.
It’s the fastest, most SEO-friendly and “cheapest” method.
You only need your API server, a static host (Netlify, Vercel, S3, Firebase Hosting, etc…), and a CI/CD system for rebuilds which you most likely already have to handle tests or deployment.
Prerendering tools
- Nuxt (yep they have an option for that): https://nuxtjs.org
- Gridesome (the best for pure static IMO): https://gridsome.org
- VuePress/VitePress: vuepress.vuejs.org / vitepress.vuejs.org
- Poi + Static Plugin: https://poi.js.org/guide/plugin-vue-static.html
Any other SSG (static site generator) would be good but, you won’t have hydration with those not Vue-driven.
APIs: You can create your own API but, usually when you do JAMStack, it’s for content-drive websites/webapps. That’s why we often use what we call: Headless CMSs.
A headless CMS, is a CMS that can render HTTP APIs as a response.
There are many of them: Strapi, Directus (Node), WordPress (yep it can), Cockpit CMS (PHP), Contentful, Dato, Prismic (hosted)…
You can find more here: https://jamstack.org/headless-cms
Conclusion: What’s the best SEO method then?
There isn’t a silver bullet. It depends on your stack, budget, team, type of app and some other parameters.
In a nutshell, I would say:
- If you don’t care a lot about it: an optimized SPA with Vue meta is fine
- If you can use Node: do Node-based SSR
- If you can’t use Node: do classic SSR with initial data rendering
- If you don’t have daily page updates or too many pages: JAMStack
That’s it. Remember: there’s never ONLY ONE WAY to do something.
https://www.smashingmagazine.com/2019/05/vue-js-seo-reactive-websites-search-engines-bots/
These frameworks allow one to achieve new, previously-unthinkable things on a website or app, but how do they perform in terms of SEO? Do the pages that have been created with these frameworks get indexed by Google? Since with these frameworks all — or most — of the page rendering gets done in JavaScript (and the HTML that gets downloaded by bots is mostly empty), it seems that they’re a no-go if you want your websites to be indexed in search engines or even parsed by bots in general.
This seems to imply that we don’t have to worry about providing Google with server-side rendered HTML anymore. However, we see all sorts of tools for server-side rendering and pre-rendering made available for JavaScript frameworks, it seems this is not the case. Also, when dealing with SEO agencies on big projects, pre-rendering seems to be considered mandatory. How come?
COMPETITIVE SEO #
Okay, so the content gets indexed, but what this experiment doesn’t tell us is: will the content be ranked competitively? Will Google prefer a website with static content to a dynamically-generated website? This is not an easy question to answer.
From my experience, I can tell that dynamically-generated content can rank in the top positions of the SERPS. I’ve worked on the website for a new model of a major car company, launching a new website with a new third-level domain. The site was fully generated with Vue.js — with very little content in the static HTML besides <title> tags and meta descriptions.
WHAT ABOUT PRE-RENDERING? #
So, why all the fuss about pre-rendering — be it done server-side or at project compilation time? Is it really necessary? Although some frameworks, like Nuxt, make it much easier to perform, it is still no picnic, so the choice whether to set it up or not is not a light one.
I think it is not compulsory. It is certainly a requirement if a lot of the content you want to get indexed by Google comes from external web service and is not immediately available at rendering time, and might — in some unfortunate cases — not be available at all due to, for example, web service downtime. If during Googlebot’s visits some of your content arrives too slowly, then it might not be indexed. If Googlebot indexes your page exactly at a moment in which you are performing maintenance on your web services, it might not index any dynamic content at all.
Furthermore, I have no proof of ranking differences between static content and dynamically-generated content. That might require another experiment. I think that it is very likely that, if content comes from external web service and does not load immediately, it might impact on Google’s perception of your site’s performance, which is a very important factor for ranking.
JAVASCRIPT ERRORS #
If you rely on Googlebot executing your JavaScript to render vital content, then major JavaScript errors which could prevent the content from rendering must be avoided at all costs. While bots might parse and index HTML which is not perfectly valid (although it is always preferable to have valid HTML on any site!), if there is a JavaScript error that prevents the loading of some content, then there is no way Google will index that content.
OTHER SEARCH ENGINES #
The other search engines do not work as well as Google with dynamic content. Bing does not seem to index dynamic content at all, nor do DuckDuckGo or Baidu. Probably those search engines lack the resources and computing power that Google has in spades.
Parsing a page with a headless browser and executing JavaScript for a couple of seconds to parse the rendered content is certainly more resource-heavy than just reading plain HTML. Or maybe these search engines have made the choice not to scan dynamic content for some other reasons. Whatever the cause of this, if your project needs to support any of those search engines, you need to set up pre-rendering.
Note: To get more information on other search engines’ rendering capabilities, you can check this article by Bartosz Góralewicz. It is a bit old, but according to my experience, it is still valid.
OTHER BOTS #
Remember that your site will be visited by other bots as well. The most important examples are Twitter, Facebook, and other social media bots that need to fetch meta information about your pages in order to show a preview of your page when it is linked by their users. These bots will not index dynamic content, and will only show the meta information that they find in the static HTML. This leads us to the next consideration.
SUBPAGES #
If your site is a so-called “One Page website”, and all the relevant content is located in one main HTML, you will have no problem having that content indexed by Google. However, if you need Google to index and show any secondary page on the website, you will still need to create static HTML for each of those — even if you rely on your JavaScript Framework to check the current URL and provide the relevant content to put in that page. My advice, in this case, is to create server-side (or static) pages that at least provide the correct title tag and meta description/information.
- If you need your site to perform on search engines other than Google, you will definitely need pre-rendering of some sort.
Vue SEO Tutorial with Prerendering
“No search engines will be able to see the content, therefore it’s not going to rank…”
Solutions:
- Server side rendering
- Pre-rendering
https://www.youtube.com/watch?v=Op8Q8bUAKNc (Google video)

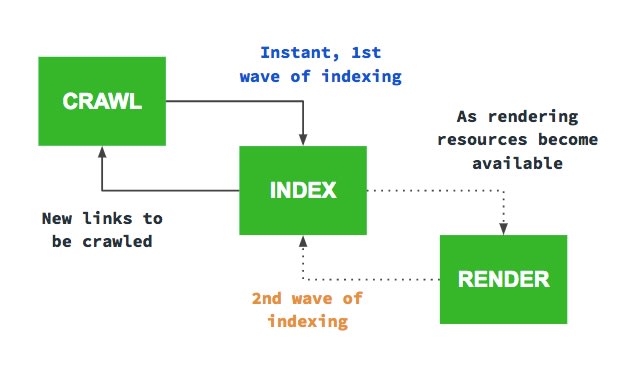
“We do not execute JS due to resource constraints” (in the first wave of indexing)
“Eventually we will do a second wave of indexing, where we execute JS and index your content again”
“…but if you have a large site or lots of frequently changing content, this might not be optimum”
A way around this is pre-rendering or server-side rendering.
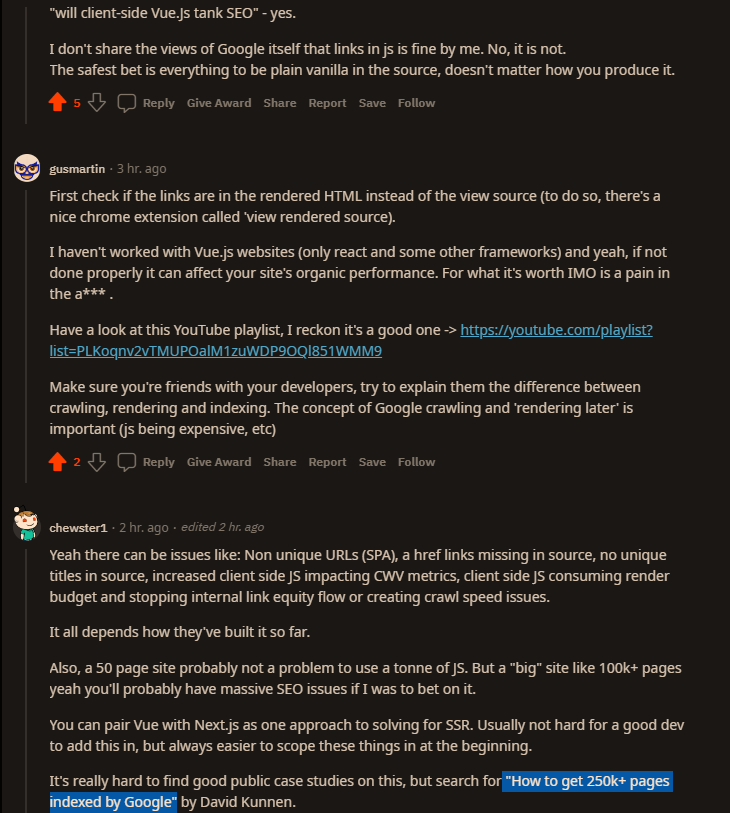
https://davidkunnen.com/how-to-get-250k-pages-indexed-by-google/
When creating Devsnap I was pretty naive. I used create-react-app for my frontend and Go with GraphQL for my backend. A classic SPA with client side rendering.
I knew for that kind of site I would have Google to index a lot of pages, but I wasn’t worried, since I knew Google Bot is rendering JavaScript by now and would index it just fine
Oh boy, was I wrong.
At first, everything was fine. Google was indexing the pages bit by bit and I got the first organic traffic.
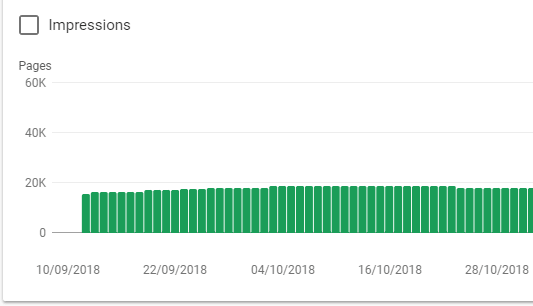
1. Enter SSR
I started by implementing SSR, because I stumbled across some quote from a Googler, stating that client side rendered websites have to get indexed twice. The Google Bot first looks at the initial HTML and immediately follows all the links it can find. The second time, after it has sent everything to the renderer, which returns the final HTML. That is not only very costly for Google, but also slow. That’s why I decided I wanted Google Bot to have all the links in the initial HTML.
I was doing that, by following this fantastic guide. I thought it would take me days to implement SSR, but it actually only took a few hours and the result was very nice.
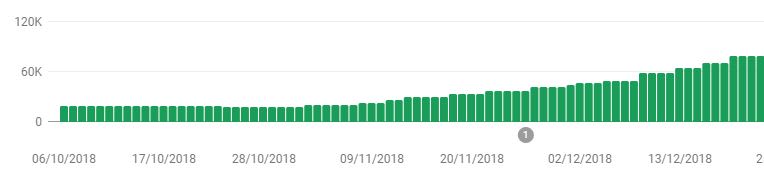
Without SSR I was stuck at around 20k pages indexed, but now it was steadily growing to >100k.
But it was still not fast enough
Google was not indexing more pages, but it was still too slow. If I ever wanted to get those 250k pages indexed and new job postings discovered fast, I needed to do more.
2. Enter dynamic Sitemap
With a site of that size, I figured I’d have to guide Google somehow. I couldn’t just rely on Google to crawl everything bit by bit. That’s why I created a small service in Go that would create a new Sitemap two times a day and upload it to my CDN.
Since sitemaps are limited to 50k pages, I had to split it up and focused on only the pages that had relevant content.
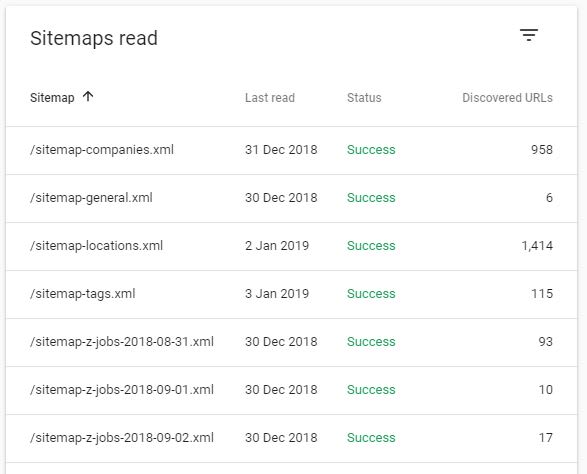
After submitting it, Google instantly started to crawl faster.
But it was still not fast enough
I noticed the Google Bot was hitting my site faster, but it was still only 5-10 times per minute. I don’t really have an indexing comparison to #1 here, since I started implementing #3 just a day later.
3. Enter removing JavaScript
I was thinking why it was still so slow. I mean, there are other websites out there with a lot of pages as well and they somehow managed too.
That’s when I thought about the statement of #1. It is reasonable that Google only allocates a specific amount of resources to each website for indexing and my website was still very costly, because even though Google was seeing all the links in the initial HTML, it still had to send it to the renderer to make sure there wasn’t anything to index left. It simply doesn’t know everything was already in the initial HTML when there is still JavaScript left.
So all I did was removing the JavaScript for Bots.
if(isBot(req)) {
completeHtml = completeHtml.replace(/<script[^>]*>(?:(?!<\/script>)[^])*<\/script>/g, “”)
}
Immediately after deploying that change the Google Bot went crazy. It was now crawling 5-10 pages – not per minute – per second.
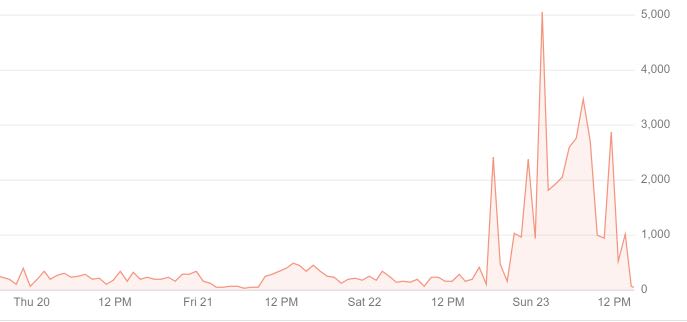
Conclusion
If you want to have Google index a big website, only feed it the final HTML and remove all the JavaScript (except for inline Schema-JS of course).
https://openai.com/blog/chatgpt/


Scripts in the <head>
John Mueller said to move scripts below the <head> whenever possible (source)
SEO JS Checks
| Javacript |
| Screaming Frog – enable Configuration>Spider>Extraction – Store HTML, Store Rendered HTML |
| Screaming Frog – enable Configuration>Spider>Rendering- enable JS crawling etc. |
| https://www.reddit.com/r/TechSEO/comments/10l45od/how_to_view_actual_javascript_links_in/ |
| Check page copy, H1s etc is present in HTML of the mobile friendly tool – https://search.google.com/test/mobile-friendly/ |
| Check the drop down filters in the Javascript Tab in Screaming Frog for any issues |
Checking JS links in Screaming Frog:

Check javascript content vs “HTML” content