Go to Configuration menu (near top right)
Extraction – Choose all the schema types.
Run crawl – check Structured Data Tab.
Check the “Features” section –


Go to Configuration menu (near top right)
Extraction – Choose all the schema types.
Run crawl – check Structured Data Tab.
Check the “Features” section –
For example – to crawl mysite.com/buyers-guides/
To crawl only URLs in the /buyers-guides/ folder on mysite.com using Screaming Frog, follow these steps:
https://www.mysite.com/buyers-guides/.*This configuration will ensure Screaming Frog only crawls URLs within the /buyers-guides/ folder on networldsports.co.uk, excluding other sections of the website.
**Note – if you are looking to crawl a country folder – e.g. https://www.apple.com/us/ – and the country-folder has URLs deeper than one folder down – e.g. https://www.apple.com/us/phones/i-phone999/
Then don’t add/set Crawl Limit to 1.
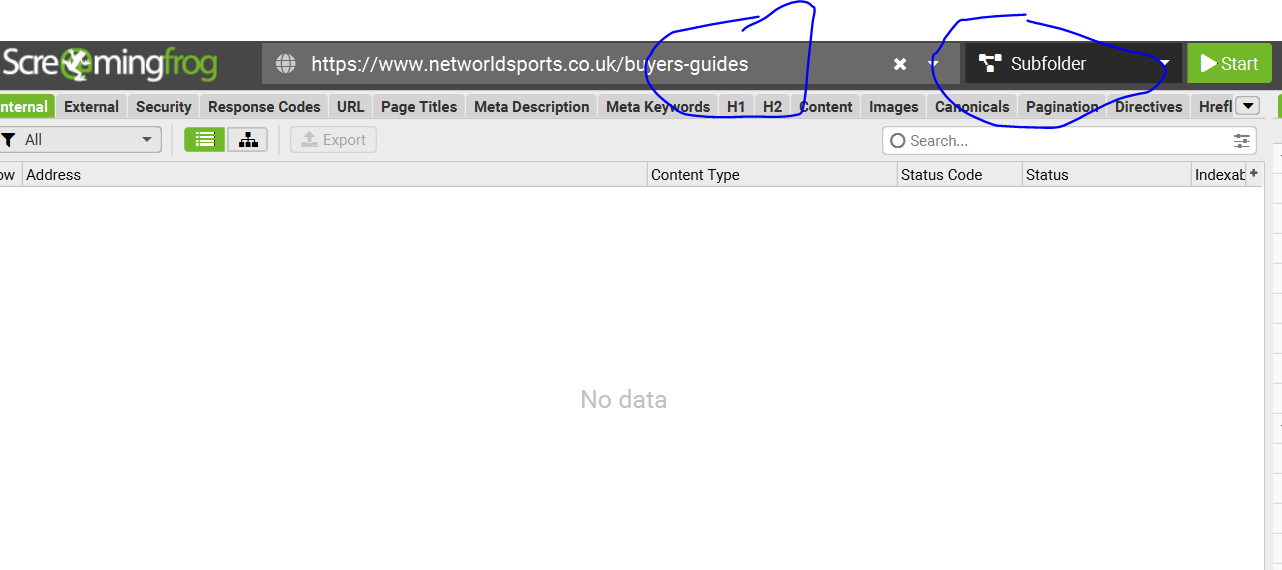
https://www.mysite.com/buyers-guides
Enter the URL of the domain plus sub/folder into the main address bar on Screaming Frog.
Choose Sub-folder option to the right of the address bar:
Go to Configuration (top menu bar, to the left) >Spider > crawl > Include
– Add the sub-folder (without trailing slash) to the include section:

Click “Start”. (Button to the right of the “Subfolder” drop down).
The protocol above would only check the status codes of any URLs actually held within the /buyers-guides/ folder.
For example, if a football goal guide, links to the FA’s website, and 404s, the above methods would not pick this up (as the FA doesn’t have /buyers-guides/ in the homepage etc)
https://www.example.com/buyers-guides
2. get the status codes of any internal and external link, that point to outside the folder?
For example:
Our football goal guide –
https://www.example.com/buyers-guides/football-pitch-size-guide
Contains links that point outside of the buyers-guides folder, like to our product pages and external links to thefa.com etc.
Crawl https://www.example.com/buyers-guides/ with ‘Crawl Outside of Start Folder’ disabled, but with ‘Check Links OutSide of Start Folder’ enabled.
Perform the crawl outlined above (using the include), get the list of https://www.example.com/buyers-guides URLs
then switch to list mode (Mode > List), go to ‘Config > Spider > Limits‘ and change the ‘Limit Crawl Depth’ from ‘0’ to ‘1” and upload and crawl the URLs
Remember to delete in include /buyers-guides from the crawl config before doing the above
i.e. Config>Spider>Include – remove anything in the box/field.
If you go to Menus – configuration > Custom > Custom Extraction
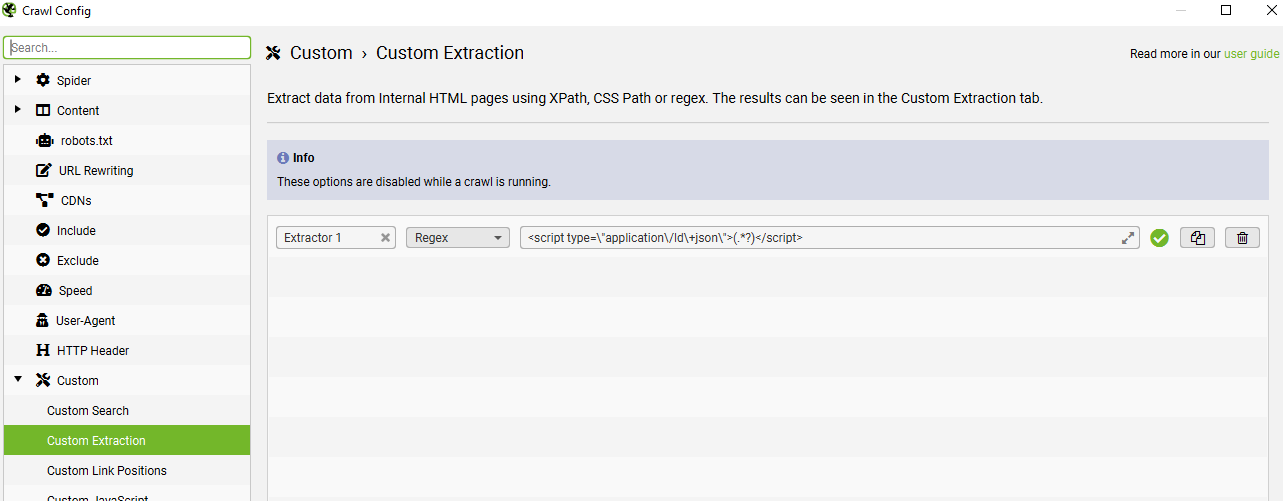
Click the +Add button on the bottom right and choose “Regex” from the drop-down menu, which is to the right of “Extractor 1” text box.
Add the code below, in the box/field to the right of “Regex”.
<script type=\"application\/ld\+json\">(.*?)</script>
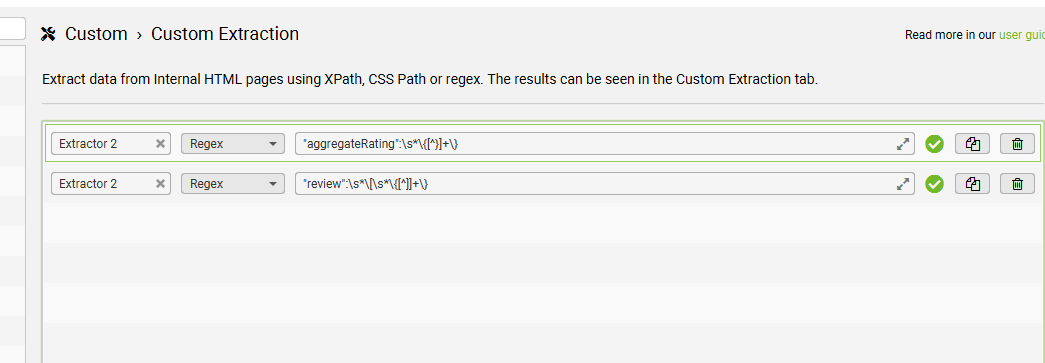
I’m using the code below, to extract product schema only – I can export to excel and filter the URLs containing product schema, but don’t have the aggregaterating:
<script type=\"application\/ld\+json\">(.*?"@type":\s*"Product".*?)<\/script>"aggregateRating":\s*\{[^}]+\}
"review":\s*\[\s*\{[^]]+\}
If the page had review schema, but not aggregateRating – then we needed to fix them.
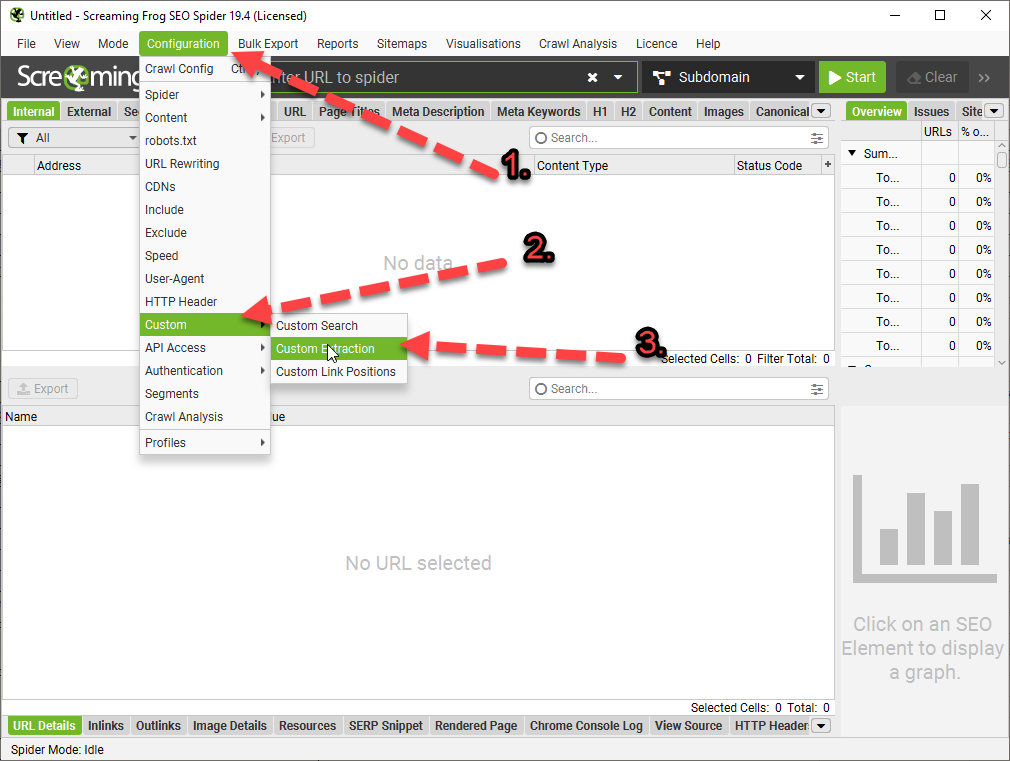
In normal crawl mode – add homepage URL to the main bar
In the top menu:
Click Configuration > Include and add folder with * at the end
E.g. to crawl just the cricket folder on a sports website add:
https://www.example.com/cricket.*


Handy if you have loads of custom extractions set up etc.
Under the Configuration Menu – go to – Profiles>Save As
Configuration > Profiles > Load…


Which can be a nice time saver too!
I pretty much always add the following to the excludes ‘file’, so it’s easier to keep it in the default setup:
^https?://[^/]+/customer/account/.*
^https?://[^/]+/checkout/cart/.*
^.\?.
.js$
.css$Last Updated – a few days ago (probably)





*Click Image to enlarge^
Once you are in the Custom Extraction Window – Choose:
//div[@class='prose']^Enter the above into the 3rd 'box' in the custom extraction window/tab. Replace "prose" with the name of the div you want to scrape.
If you copy the Xpath using Inspect Element – select the exact element you want. For example, don’t select the Div that contains text you want to scrape – select the text itself:

Here are some more examples:
(Please Note – the formatting changes the single quote marks ‘ ‘ – you may need to override them manually with single quotes using your keyboard, before adding to Screaming Frog. For example
//div[@class=’read-more’]
Should be:
//div[@class='read-more']
| XPath | Output |
|---|---|
| //h1 | Extract all H1 tags |
| //h3[1] | Extract the first H3 tag |
| //h3[2] | Extract the second H3 tag |
| //div/p | Extract any <p> contained within a <div> |
| //div[@class=’author’] | Extract any <div> with class “author” (remember to check ‘ quote marks are correct) |
| //p[@class=’bio’] | Extract any <p> with class “bio” |
| //*[@class=’bio’] | Extract any element with class “bio” |
| //ul/li[last()] | Extract the last <li> in a <ul> |
| //ol[@class=’cat’]/li[1] | Extract the first <li> in a <ol> with class “cat” |
| count(//h2) | Count the number of H2’s (set extraction filter to “Function Value”) |
| //a[contains(.,’click here’)] | Extract any link with anchor text containing “click here” |
| //a[starts-with(@title,’Written by’)] | Extract any link with a title starting with “Written by” |
| XPath | Output |
|---|---|
| //@href | Extract all links |
| //a[starts-with(@href,’mailto’)]/@href | Extract link that starts with “mailto” (email address) |
| //img/@src | Extract all image source URLs |
| //img[contains(@class,’aligncenter’)]/@src | Extract all image source URLs for images with the class name containing “aligncenter” |
| //link[@rel=’alternate’] | Extract elements with the rel attribute set to “alternate” |
| //@hreflang | Extract all hreflang values |
I recommend setting the extraction filter to “Extract Inner HTML” for these ones.
Extract Meta Tags:
| XPath | Output |
|---|---|
| //meta[@property=’article:published_time’]/@content | Extract the article publish date (commonly-found meta tag on WordPress websites) |
Extract Open Graph:
| XPath | Output |
|---|---|
| //meta[@property=’og:type’]/@content | Extract the Open Graph type object |
| //meta[@property=’og:image’]/@content | Extract the Open Graph featured image URL |
| //meta[@property=’og:updated_time’]/@content | Extract the Open Graph updated time |
Extract Twitter Cards:
| XPath | Output |
|---|---|
| //meta[@name=’twitter:card’]/@content | Extract the Twitter Card type |
| //meta[@name=’twitter:title’]/@content | Extract the Twitter Card title |
| //meta[@name=’twitter:site’]/@content | Extract the Twitter Card site object (Twitter handle) |
How to Extract Schema Markup in Microdata Format
If it’s in JSON-LD format, then jump to the section on how to extract schema markup with regex.
Extract Schema Types:
| XPath | Output |
|---|---|
| //*[@itemtype]/@itemtype | Extract all of the types of schema markup on a page |
References:
Update:
If the ‘shorter code’ in the tables above doesn’t work for some reason, you may have to right click – inspect and copy the full Xpath code to be more specific with what you want to extract:

For sections of text like paragraphs and on page descriptions, select the actual text in the inspect window before copying the Xpath.
Update 2
We wanted to compare the copy and internal links before and after a site-migration to a new CMS.
To see the links in HTML format – you just need to check “Extract Text” to “Extract Inner HTML” in the final drop down:
(click image to enlarge)

On the new CMS, it was easier to just copy the XPath

I’m glad you asked.
We used it to check that page copy had migrated properly to a new CMS.
We also extracted the HTML within the copy, to check the internal links were still present.
One cool thing you can do – is scrape reviews and then analyse the reviews to see key feedback/pain points that could inform superior design.
Here’s a good way to use custom extraction/search to find text that you want to use for anchor text for internal links:

I’m still looking into how to analyse the reviews – but this tool is a good starting point: https://seoscout.com/tools/text-analyzer
Throw the reviews in and see what words are repeated etc
This tool is also very good:
Or – just paste into Chat GPT and ask for insights and pain-points to help develop a better product.
I asked Chat GPT and Google Gemini why I would want to scrape copy from sites and got these responses:
Monitoring Competitors
Content Strategy Insights: Gather headings, titles, and meta descriptions from competitor websites to gain insights into their content strategies and how they optimize for search engines.
Pricing Information: For e-commerce platforms, you can use custom extraction to keep an eye on competitors’ pricing strategies by pulling prices for similar products.
Promotional Strategies: Collect details on promotions, discounts, or special offers from competitors’ sites to evaluate how they stack up against your own promotional efforts.
Keyword Usage: Identify specific keywords from competitors’ content to understand how they are targeting particular topics or niches.
Backlink Analysis: While Screaming Frog isn’t primarily a backlink tool, you can utilize custom extraction to pinpoint external links on a page, providing insights into a competitor’s backlink strategy.
Optimizing Your Own Website
Content Optimization: Employ custom extraction to review your own site’s headings, titles, meta descriptions, and keyword usage to spot areas that need improvement.
Structural Data: Extract and assess structured data (like Schema markup) across your site to ensure proper implementation and identify potential enhancement opportunities.
Internal Linking: Analyze internal linking structures to understand the flow of page authority throughout your site and to find orphan pages or those with insufficient internal link support.
Audit Forms and Calls to Action (CTAs): Extract form action URLs and CTA links to verify they are working correctly and to optimize their placement and wording.
Identify Outdated Content: Use custom extraction to locate dates and timestamps on your content, which can help you identify articles or pages that may require updates.
Gemini said:
The custom extraction feature in Screaming Frog provides numerous advantages for website analysis and data collection. Here are some important reasons to utilize it:
Go beyond basic SEO metrics: While Screaming Frog offers valuable insights, custom extraction enables you to focus on specific data points that may not be easily accessible, such as product prices, article publish dates, or user reviews.
Gain deeper competitor insights: Extract information on competitor pricing strategies, product descriptions, or content structures to compare with your own website.
Gather information for internal analysis: Monitor specific elements on your site, like call to action (CTA) button text or internal linking structures, to observe changes and assess their impact.
Save time and effort: Collecting data manually can be labor-intensive and prone to errors. Custom extraction streamlines the process, allowing you to efficiently gather information across numerous pages.
Maintain consistent data: By setting up automated data extraction, you ensure uniform data collection over time, which facilitates better trend analysis and comparisons.
Combine extracted data with existing Screaming Frog metrics: Merge the extracted data with other SEO parameters such as page titles, meta descriptions, and internal links for a more thorough analysis.
Create custom reports: Use the extracted data to generate tailored reports for specific purposes, like competitor pricing comparisons or evaluations of content performance.
Monitoring Competitors:
Custom extraction serves as a valuable tool for competitor monitoring in various ways:
Extract competitor pricing data: Keep track of competitor pricing trends, identify potential gaps in your own pricing strategy, and make informed pricing decisions.
Analyze competitor content structure and keywords: Learn how competitors format their content, pinpoint their targeted keywords, and gain insights to enhance your own strategy.
Note for self – for Magento 2, Hyva theme Sub-category page copy – scrape using:
//div[@id='descriptionDiv']Product page descriptions upper and lower divs -//div[@class="product-description"]//*[@id="specifications"]/div/div[2]/div/div/div/div/div//*[@id="description"]/div/div[2]
For personal reference –
//div[@class=’product-description’]
//div[@class=’prose’]
/html/body/div[1]/div[3]/main/div[4]/div/div
//div[@class=’category-description read-more’]
Configuration → Custom → Extraction → Add (one per row). All extract as Extract Text unless noted.
| Name | Type | Selector | Extractor |
|---|---|---|---|
| Meta Description | XPath | //meta[@name='description']/@content | Extract Text |
| Meta Keywords | XPath | //meta[@name='keywords']/@content | Extract Text |
| OG Title | XPath | //meta[@property='og:title']/@content | Extract Text |
| OG Description | XPath | //meta[@property='og:description']/@content | Extract Text |
| H1 Full | CSSPath | h1 | Extract Text |
| All H2s | XPath | //h2 | Extract Text |
| All H3s | XPath | //h3 | Extract Text |
| Product Description Body | CSSPath | .product-description | Extract Text |
| USP / Special Feature Blocks | CSSPath | .special-feature-item | Extract Text |
| Review Titles | CSSPath | [itemprop='name'] | Extract Text |
| Review Bodies | CSSPath | [itemprop='reviewBody'] | Extract Text |
| Breadcrumbs | CSSPath | nav.breadcrumbs | Extract Text |
| Image Alts | XPath | //img/@alt | Extract Text |
| Image Titles | XPath | //img/@title | Extract Text |
| Schema.org description | XPath | //script[@type='application/ld+json'] | Extract Inner HTML |
These use XPath’s contains() to return a value only when specific English words appear in body text. Handy for flagging pages fast:
| Name | Type | Selector |
|---|---|---|
| Has “the “ | XPath | //body[contains(., ' the ')]/@class |
| Has “and “ | XPath | //body[contains(., ' and ')]/@class |
| Has “with “ | XPath | //body[contains(., ' with ')]/@class |
| Has “made “ | XPath | //body[contains(., ' made ')]/@class |
| Has “quality “ | XPath | //body[contains(., ' quality ')]/@class |
| Has “features “ | XPath | //body[contains(., ' features ')]/@class |
| Has “delivery “ | XPath | //body[contains(., ' delivery ')]/@class |
Update – I don’t think all the process below is required.
Just download the 404 – inlinks report from Screaming Frog
Bulk Export (very top, slightly to the left on the GUI)> Response Codes > Internal > Client Error 4**s
Copy the “Destination” (column C on report) column and paste into an new Excel tab/sheet and remove duplicates
In the first sheet, copy and paste the source column into column D
In the second sheet, do a vlookup using the first destination URL, and “lookup” in the first sheet – columns C and D, to return the relevant source URL
Copy the vlookup and Paste – values – into column A into the second sheet
You can also copy and paste the anchor text and location into column C
Follow this protocol, to produce a sheet you can send to devs etc, to remove 404s
Run a crawl with Screaming Frog
Export the report –> Screaming Frog – Bulk Export – Response Codes – Internal – Internal Client Error (4xxs) (check 500s too)
In Excel – Copy and paste the “destination” URLs into a new sheet – into column A
Remove duplicates from the destination URLs that you’ve just copied into a new sheet
rename the colum – 404s Destination
Paste Source URLs in column A, and Anchor Text into column C
In cell B1 type – ” | ”
In cell D1 – give the column the heading “Source | Anchor”
In cell D2 concatenate – =CONCATENATE(A2,$B$1,C2)
Drag the formula down.
You’ll now have the anchor text and the source URL together, so you can vlookup the destination (404) URL
You need “destination” in column B and “Source | Anchor Text” in column C, as vlookup has to go left to right
Name column D in the new sheet “Example Source URL & Anchor Text” and in cell D2 enter the lookup – VLOOKUP(B2,B:C,2,0) (put “equals sign” before the V. Drag the formula down
Copy column A and paste into a new sheet. Name the sheet “Final”.
Copy column D with the vlookup and paste values into column B in the “Final Spreadsheet”
In “final”, you should now have all the unique 404s and an example of a page that links to those 404s with the anchor text.
look out for 404s that are classed as HTTP Redirects in the “type” column – these don’t seem to have a unique source URL. You may have to search for the URL in the search box in Screaming Frog and click the “inlinks” tab to see original link to the non-secure http page
If you like, before you send off the report to someone, you can double check the “destination” URLs definitely are 404s, by pasting them into screaming frog in “list” mode
Export the 404 Inlinks Report into Excel
The best report in Screaming Frog to see the source and destination of all 404s – is to go to Bulk Export at the top menu:

And then Response Codes – Client Error Inlinks

In the Exported Excel Sheet:
Copy the “destination” column
Paste into a new sheet/tab – In Column B
Remove duplicates
Back in the first sheet – Paste “Source”, into column D to the right of “destination” in first tab/sheet
In the second sheet –
Do a vlookup in the second sheet/tab – to import a source URL to each unique “destination” URL
Add the word “source” to cell C1 in the second sheet
I think you have to click the file name to download the example sheet below:
Sheet / Tab 1 should look like this:
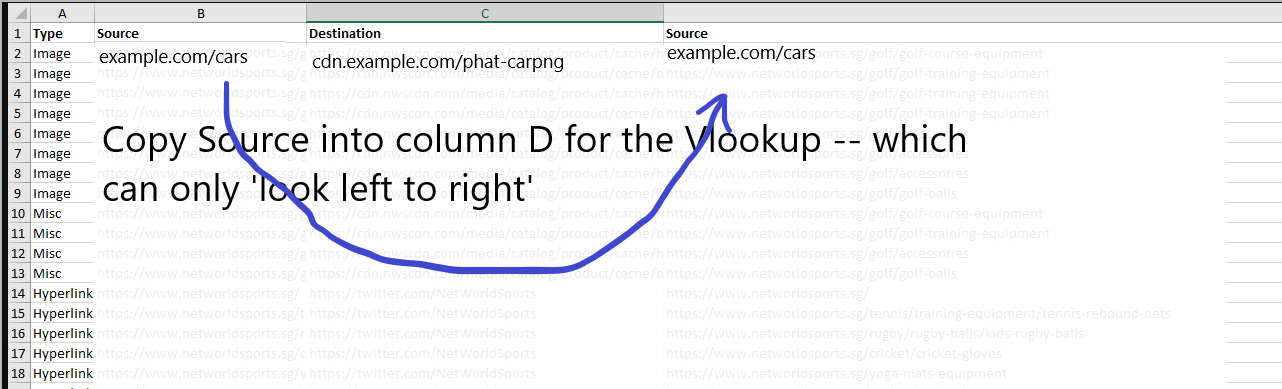
The Second Sheet / Tab should look like this:

The Lookup Value in Cell C2, in the sheet above is:
=VLOOKUP(Sheet1!B2,’1 – Client Error (4xx) Inlinks’!C:D,2,0)
Just double click / drag it down to complete the lookup
You can add more lookups and columns to provide more details about the link location.
Just copy and paste values on the last Vlookup.
Paste another column like “Anchor” into column D on the first Tab
Paste the vlookup into the adjacent column
“0” means nothing found – i.e. no anchor text etc

Update –
404s found in the Navigation or “Aside” tend to be site-wide, so you can find one instance of this and update the 404 and Bob’s your uncle.
If a 404 is within the page content/copy however, they are possibly unique and need fixing individually. So take a look the Content 404s separately. They probably only have 1 source URL so no need to faff with vlookups etc.
TLDR – Easiest way to check hreflang is to just go to reports > Hreflang > non200 Hreflang URLs:

Filter “Source” column to your current domain and then you should see all the hreflang that 300 or 404.

Checklist here – https://docs.google.com/spreadsheets/d/1IHRZNFravVKaZ5T9uOEOg_zQ5ee8dHcRP8m92vkn4KY/edit#gid=0
Configuration – spider – crawl and store Hreflang
For the indexable URLs found above, check hreflang using:
https://technicalseo.com/tools/hreflang/
Order by Occurrences – check if any URLs have less hreflang then they should have

Download the non-200 hreflang report – by going to the “hreflang” tab in Screaming Frog.
Delete all the columns except those containing the actual hreflang URLs
Then in the column adjacent to all the hreflang URLs add the formula:
=INDEX($A$1:$G$126,CEILING(ROW()/7, 1),MOD(ROW()-1,7)+1)
The formula above would be used if the hreflang URLs are in columns A to G, and the last row that is populated in number 126.
You’ll also need to update the number 7 in the formula – for example if you have 5 columns of hreflang URLs, then change 7 to 5.
Drag this formula down until you start seeing #REF! errors, indicating you’ve covered all the data in your original columns
Export the List mode ‘crawl’ from Screaming Frog and filter by status code
Official documentation from Screaming Frog here.
You can also use this Google sheet to check hreflang further
SCREAMING Frog mother fuckers!
To exclude URLs just go to:
Configuration > Exclude (in the very top menu bar)

To exclude URLs within a specific folder, use the following regex:
^https://www.mydomain.com/customer/account/.*
^https://www.mycomain.com/checkout/cart/.*
The above regex, will stop Screaming Frog from Crawling the customer/account folder and the cart folder.
Or – this is easier for me, as I have to check and crawl lots of international domains with the same site structure and folders:
^https?://[^/]+/customer/account/.*
^https?://[^/]+/checkout/cart/.*
Ive just been using the image extensions to block them in the crawl, e.g.
.*jpg
Although you can block them in the Configuration>Spider menu too.
this appears to do the job:
^.*\?.*
My typical “Excludes” looks like this:
^https?://[^/]+/customer/account/.*
^https?://[^/]+/checkout/cart/.*
^.*\?.*jpg$
png$
.js$
.css$

Update – you can just use this to block any URLs containing “cart” or “account”
/account/|/cart/
Update:
Currently using this for my excludes config, as I actually want to crawl images:
^https?://[^/]+/customer/account/.*
^https?://[^/]+/checkout/cart/.*
^.\?.
.js$
.css$
To exclude any URLs using ? and + (as per our weird URLs with parameters) use – .*[\?\+].*
For personal reference –
//div[@class=’product-description’]
//div[@class=’prose’]
/html/body/div[1]/div[3]/main/div[4]/div/div
//div[@class=’category-description read-more’]
