I have made a load of notes about SEO and Pagination from around the web, I’ve summarised them here…
Summary
- Don’t point canonical tags to the first page – give them their own canonical URL
- Block filtered pages and sorted pages – e.g. sorted by price e.g. “support ?order=price”
- It is still best to use rel=next and rel=prev
- Have unique meta tags, including title tags and meta descriptions – e.g.
Socks for Sale – Page 3 | Sockstore
(that would be an example for the 3rd page of a sock store, called sockstore) - Check log files to see if paginated pages are being crawled
- Consider using preload, preconnect, or prefetch to optimize the performance for a user moving to the next page.
- Consider adding a UX friendly amount of unique copy to each page
- Don’t place the link attributes in the <body> content.
- They’re only supported by search engines within the <head> section of your HTML.
- Don’t Include Paginated Pages in XML Sitemaps
- Consider using a sitemap file or a Google Merchant Center feed to help Google find all of the products on your site
source – https://developers.google.com/search/docs/advanced/ecommerce/pagination-and-incremental-page-loading
- If possible give paginated pages their own “sub-optimal” meta titles & descriptions
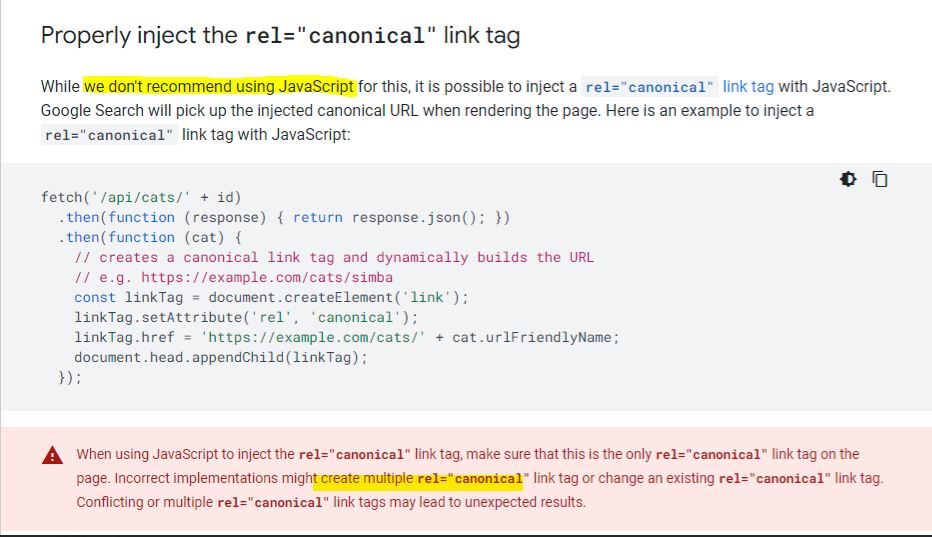
- It’s not best practice to use JS to inject/create canonical URLs
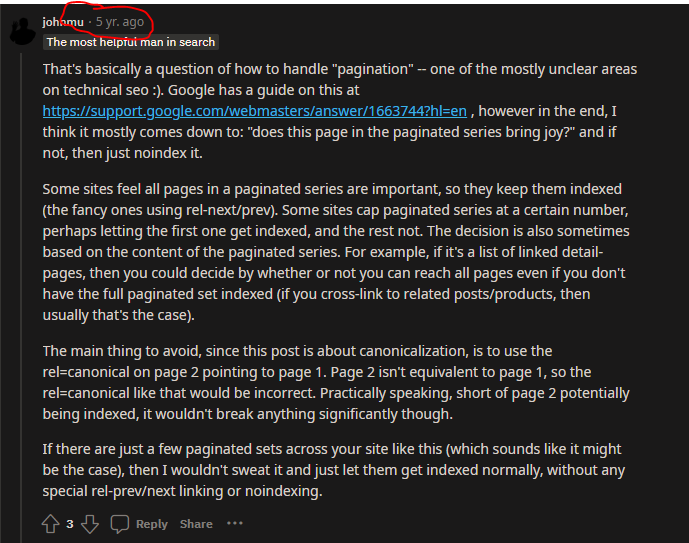
- Don’t have multiple canonical URLs (see reddit thread here)
John Mueller commented, “We don’t treat pagination differently. We treat them as normal pages.”
Meaning paginated pages are not recognized by Google as a series of pages consolidated into one piece of content as they previously advised. Every paginated page is eligible to compete against the root page for ranking.
To encourage Google to return the root page in the SERPs and prevent “Duplicate meta descriptions” or “Duplicate title tags” warnings in Google Search Console, make an easy modification to your code.
| Pagination Checklist |
| Uses a href HTML links? |
| Links need to be in the <head> |
| works with JS disabled? |
| Different page numbers have self-referencing canonical URLs? |
| Do Not Include Paginated Pages in Sitemaps |
| Optimize Meta Tags, If Possible – Different title on each page |
| Ensure that the robots’ meta-tag doesn’t contain noindex |
| Link to first page should be root page, not a parameter ?p=1 page |
| “Previous button” < on page 2 – should like to root page, not ?p=1 |
| You shouldn’t have a View All Page |
Further Notes on Pagination
If the root page has the title:

The successive paginated pages could have titles like:

These paginated URL page titles and meta descriptions are purposefully suboptimal to dissuade Google from displaying these results, rather than the root page.
If even with such modifications, paginated pages are ranking in the SERPs, try other traditional on-page SEO tactics such as:
- De-optimize paginated page H1 tags.
- Add useful on-page text to the root page, but not paginated pages.
- Add a category image with an optimized file name and alt tag to the root page, but not paginated pages.
Source – https://www.searchenginejournal.com/technical-seo/pagination
eCommerce Pagination Best Practices (Notes from Google.com)
https://developers.google.com/search/docs/advanced/ecommerce/pagination-and-incremental-page-loading
You can improve the experience of users on your site by displaying a subset of results to improve page performance (page experience is a Google Search ranking signal), but you may need to take action to ensure the Google crawler can find all your site content.
For example, you may display a subset of available products in response to a user using the search box on your ecommerce site – the full set of matches may be too large to display on a single web page, or take too long to retrieve.
Beyond search results, you may load partial results on your ecommerce site for:
- Category pages where all products in a category are displayed
- Blog posts or newsletter titles that a site has published over time
- User reviews on a product page
- Comments on a blog post
Having your site incrementally load content, in response to user actions, can benefit your users by:
- Improving user experience as the initial page load is faster than loading all results at once.
- Reducing network traffic, which is particularly important for mobile devices.
- Improving backend performance by reducing the volume of content retrieved from databases or similar.
- Improving reliability by avoiding excessively long lists that may hit resource limits leading to errors in the browser and backend systems.
Selecting the best UX pattern for your site
To display a subset of a larger list, you can choose between different UX patterns:
- Pagination: Where a user can use links such as “next”, “previous”, and page numbers to navigate between pages that display one page of results at a time.
- Load more: Buttons that a user can click to extend an initial set of displayed results.
- Infinite scroll: Where a user can scroll to the end of the page to cause more content to be loaded. (Learn more about infinite scroll search-friendly recommendations.)
| UX Pattern | ||
| Pagination | Pros: Gives users insight into result size and current position | Cons: More complex controls for users to navigate through resultsContent is split across multiple pages rather than being a single continuous listViewing more requires new page loads |
| Load more | Pros: Uses a single page for all contentCan inform user of total result size (on or near the button) | Cons: Can’t handle very large numbers of results as all of the results are included on a single web page |
| Infinite scroll | Pros: Uses a single page for all contentIntuitive – the user just keeps scrolling to view more content | Cons: Can lead to “scrolling fatigue” because of unclear result sizeCan’t handle very large numbers of results |
How Google indexes the different strategies
Once you’ve selected the most appropriate UX strategy for your site and SEO, make sure the Google crawler can find all of your content.
For example, you can implement pagination using links to new pages on your ecommerce site, or using JavaScript to update the current page. Load more and infinite scroll are generally implemented using JavaScript. When crawling a site to find pages to index, Google only follows page links marked up in HTML with <a href> tags. The Google crawler doesn’t follow buttons (unless marked up with <a href>) and doesn’t trigger JavaScript to update the current page contents.
If your site uses JavaScript, follow these JavaScript SEO best practices. In addition to best practices, such as making sure links on your site are crawlable, consider using a sitemap file or a Google Merchant Center feed to help Google find all of the products on your site.
Best practices when implementing pagination
To make sure Google can crawl and index your paginated content, follow these best practices:
- Link pages sequentially
- Use URLs correctly
- Avoid indexing URLs with filters or alternative sort orders
Link pages sequentially
To make sure search engines understand the relationship between pages of paginated content, include links from each page to the following page using <a href> tags. This can help Googlebot (the Google web crawler) find subsequent pages.

In addition, consider linking from all individual pages in a collection back to the first page of the collection to emphasize the start of the collection to Google. This can give Google a hint that the first page of a collection might be a better landing page than other pages in the collection.
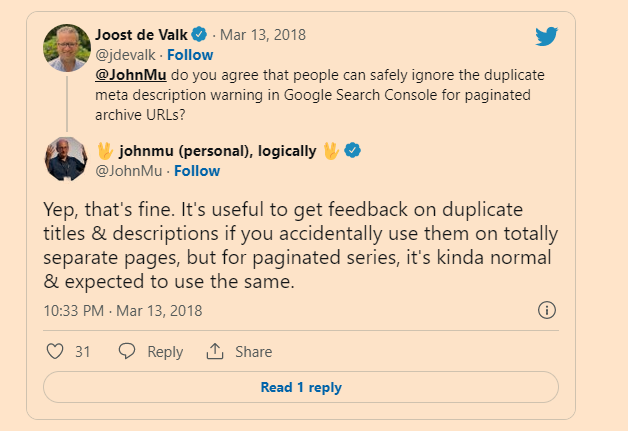
Normally, we recommend that you give web pages distinct titles to help differentiate them. However, pages in a paginated sequence don’t need to follow this recommendation. You can use the same titles and descriptions for all pages in the sequence. Google tries to recognize pages in a sequence and index them accordingly.
Use URLs correctly
- Give each page a unique URL. For example, include a ?page=n query parameter, as URLs in a paginated sequence are treated as separate pages by Google.
- Don’t use the first page of a paginated sequence as the canonical page. Instead, give each page in its own canonical URL.
- Don’t use URL fragment identifiers (the text after a # in a URL) for page numbers in a collection. Google ignores fragment identifiers. If Googlebot sees a URL to the next page that only differs by the text after the #, it may not follow the link, thinking it has already retrieved the page.
- Consider using preload, preconnect, or prefetch to optimize the performance for a user moving to the next page.
In the past, Google used <link rel=”next” href=”…”> and <link rel=”prev” href=”…”> to identify next page and previous page relationships. Google no longer uses these tags, although these links may still be used by other search engines.
Avoid indexing URLs with filters or alternative sort orders
You may choose to support filters or different sort orders for long lists of results on your site. For example, you may support ?order=price on URLs to return the same list of results ordered by price.
To avoid indexing variations of the same list of results, block unwanted URLs from being indexed with the noindex robots meta tag or discourage crawling of particular URL patterns with a robots.txt file.
Pros of infinite scroll
- It’s more usable on mobile. One of the biggest advantages of infinite scrolling is that it’s incredibly usable on mobile devices. Simply scrolling down to view more content is far easier than asking users to click on a tiny “next” button or number every time they want to go to the next page.
- Infinite scroll is better for user engagement. There’s a reason why Aussies spend hours on end scrolling through social media. Having content continuously load means that users can browse and engage with your site without being interrupted. This can be beneficial for content marketing and SEO, particularly given that Google is now using user behaviour as a ranking signal.
Cons of infinite scroll
- Difficulties with crawling. Like pagination, the infinite scroll can also create problems when it comes to having your site crawled by Google (or other search engines). Search bots only have a limited time to crawl a page. If your content is too lengthy or takes too long to load, it loses the opportunity to be crawled — meaning entire chunks of your content might go unindexed.
- It can be hard to find information. Depending on the length of your page, an infinite scroll can make it difficult for users to go back and revisit previous sections or products that they’re interested in. You might end up losing valuable leads or conversions simply because users found it too difficult to find what they were looking for, and chose to look elsewhere.
- Limited access to the footer. Website footers contain valuable information for site visitors, such as social media network buttons, shipping policies, FAQs and contact information. However, with infinite scroll, it’s tough for users to access this section on your site.
At the end of the day, while users might appreciate infinite scrolling, this option isn’t as beneficial for SEO as website pagination. Pagination is the ideal option for search engines, provided you handle paginated pages in line with SEO best practices.
Best practices to consider for SEO pagination
1. Include canonical tags on paginated pages
Duplicate content is likely to be one of the biggest challenges you’ll come across when implementing pagination on your website.
To overcome these issues, you’ll need to use a self-referencing rel = “canonical” attribute on all of your paginated pages that directs back to the “View All” version of your page. This tag tells Google to crawl and index the “View All” version only and ignore any duplicated content in your paginated pages.
***If you choose to use a View All page**
In the HTML, it looks like this:

Image source: SEO Clarity
Last but not least, make sure you use internal linking to different paginated URLs using the rel=”next” and rel=”prev” tags along with your canonical tag. These can be incorporated into your HTML like so:
<link rel=”next” href=”https://www.example.com/category?page=2&order=newest” />
<link rel=”canonical” href=”https://www.example.com/category?page=2″ />
Even though these aren’t a ranking factor, they still help Google (and Bing) understand the order of paginated content on your website.
2. Make sure to use crawlable anchor links
The first step to getting Google to crawl and index pages that are paginated? Make sure that the search engine can access them. Throughout your website, you should link to your paginated category pages using crawlable anchor site links with href attributes.
Let’s say you’re linking to page 3 of your product catalogue. Crawlable paginated links would look like this:
<a href=”https://www.mystorehere.com/catalog/products?page=4>
On the flipside, any link without the “a href” attribute won’t be crawlable by Google, such as this link:
<span href=”https://www.mystorehere.com/catalog/products?page=4>
3. Don’t include paginated pages in your sitemap
Even though your paginated pages are indexable, paginated URLs shouldn’t be included on your XML sitemap. Adding them in will only use up your ‘crawl budget’ with Google and could even lead to Google picking a random page to rank (such as page 3 in your product catalogue).
The only exception to this is when you choose to have important pages consolidated into a “View All” page, which absolutely needs to be included in your XML sitemap.
A final word on this one: don’t noindex paginated pages. While the no-index tag tells Google not to index paginated pages, it could lead to Google eventually no-following internal links from that page. In turn, this might cause other pages that are linked from your paginated pages to be removed from Google’s index.
4. Ensure you optimise your on-page SEO
Even if your paginated pages use self-referencing canonical URL tags, feature crawlable anchor links and are excluded from your XML sitemap, you should still follow best practices for on-page SEO.
As we touched on earlier, paginated pages are treated as unique pages in Google’s search index. This means that each page needs to follow on-page SEO guidelines if you want to rank in search results.
In case you needed more proof, here are John Mueller’s recommendations on this topic:
“I’d also recommend making sure the pagination pages can kind of stand on their own. So similar to two category pages where if users were to go to those pages directly, there would be something useful for the user to see there. So it’s not just like a list of text items that go from zero to 100 and links to different products. It’s actually something useful kind of like a category page where someone is looking for a specific type of a product they can go there, and they get that information.” – John Mueller, Google Webmaster English Hangouts
This means that every paginated page should:
- Have unique meta tags, including title tags and meta descriptions
- Feature mobile-friendly design that’s optimised for smaller screens
- Load quickly on desktop and mobile devices
- Include filters to help narrow down products (if you’re running an online store)
- Deliver value for visitors
Tip: If you’re running an online store with eCommerce category pages, Google’s UX Playbook for Retail contains all the best practices you need to know to turn clicks into customers.
https://www.searchenginejournal.com/technical-seo/pagination/
SEO-Friendly Pagination: A Complete Best Practices Guide
Summary
- Canonical tags to the same page (not to the view all or first page)
- Use rel=next and rel=prev
- If possible give paginated pages their own “sub-optimal” meta titles & descriptions
- Not sure if this is an issue:
Pagination Causes Duplicate Content
Correct if pagination has been improperly implemented, such as having both a “View All” page and paginated pages without a correct rel=canonical or if you have created a page=1 in addition to your root page.
Incorrect when you have SEO friendly pagination. Even if your H1 and meta tags are the same, the actual page content differs. So it’s not duplication.
Pagination Creates Thin Content
Correct if you have split an article or photo gallery across multiple pages (in order to drive ad revenue by increasing pageviews), leaving too little content on each page.
Incorrect when you put the desires of the user to easily consume your content above that of banner ad revenues or artificially inflated pageviews. Put a UX-friendly amount of content on each page.
Pagination Uses Crawl Budget
Correct if you’re allowing Google to crawl paginated pages. And there are some instances where you would want to use that budget.
For example, for Googlebot to travel through paginated URLs to reach deeper content pages.
Often incorrect when you set Google Search Console pagination parameter handling to “Do not crawl” or set a robots.txt disallow, in the case where you wish to conserve your crawl budget for more important pages. (use robots.txt for this as no longer in Search Console)
Managing Pagination According to SEO Best Practices
Use Crawlable Anchor Links

For search engines to efficiently crawl paginated pages, the site must have anchor links with href attributes to these paginated URLs.
Be sure your site uses <a href=”your-paginated-url-here”> for internal linking to paginated pages. Don’t load paginated anchor links or href attribute via JavaScript.
Additionally, you should indicate the relationship between component URLs in a paginated series with rel=”next” and rel=”prev” attributes.
Yes, even after Google’s infamous Tweet that they no longer use these link attributes at all.
Google is not the only search engine in town. Here is Bing’s take on the issue.

Complement the rel=”next” / “prev” with a self-referencing rel=”canonical” link.
So /category?page=4 should rel=”canonical” to /category?page=4.
This is appropriate as pagination changes the page content and so is the master copy of that page.
If the URL has additional parameters, include these in the rel=”prev” / “next” links, but don’t include them in the rel=”canonical”.
For example:
<link rel=”next” href=”https://www.example.com/category?page=2&order=newest” />
<link rel=”canonical” href=”https://www.example.com/category?page=2″ />
Doing so will indicate a clear relationship between the pages and prevent the potential of duplicate content.
Common errors to avoid:
- Placing the link attributes in the <body> content. They’re only supported by search engines within the <head> section of your HTML.
- Adding a rel=”prev” link to the first page (a.k.a. the root page) in the series or a rel=”next” link to the last. For all other pages in the chain, both link attributes should be present.
- Beware of your root page canonical URL. Chances are on ?page=2, rel=prev should link to the canonical, not a ?page=1.
The <head> code of a four-page series will look something like this:
- One pagination tag on the root page, pointing to the next page in series.
- <link rel=”next” href=”https://www.example.com/category?page=2″>
- <link rel=”canonical” href=”https://www.example.com/category”>
- Two pagination tags on page 2.
- <link rel=”prev” href=”https://www.example.com/category”>
- <link rel=”next” href=”https://www.example.com/category?page=3″>
- <link rel=”canonical” href=”https://www.example.com/category?page=2″>
- Two pagination tags on page 3.
- <link rel=”prev” href=”https://www.example.com/category?page=2″>
- <link rel=”next” href=”https://www.example.com/category?page=4″>
- <link rel=”canonical” href=”https://www.example.com/category?page=3″>
- One pagination tag on page 4, the last page in the paginated series.
- <link rel=”prev” href=”https://www.example.com/category?page=3″>
- <link rel=”canonical” href=”https://www.example.com/category?page=4″>
Modify Paginated Pages On-Page Elements
John Mueller commented, “We don’t treat pagination differently. We treat them as normal pages.”
Meaning paginated pages are not recognized by Google as a series of pages consolidated into one piece of content as they previously advised. Every paginated page is eligible to compete against the root page for ranking.
To encourage Google to return the root page in the SERPs and prevent “Duplicate meta descriptions” or “Duplicate title tags” warnings in Google Search Console, make an easy modification to your code.
If the root page has the formula:
The successive paginated pages could have the formula:
These paginated URL page titles and meta description are purposefully suboptimal to dissuade Google from displaying these results, rather than the root page.
If even with such modifications, paginated pages are ranking in the SERPs, try other traditional on-page SEO tactics such as:
- De-optimize paginated page H1 tags.
- Add useful on-page text to the root page, but not paginated pages.
- Add a category image with an optimized file name and alt tag to the root page, but not paginated pages.
Don’t Include Paginated Pages in XML Sitemaps
While paginated URLs are technically indexable, they aren’t an SEO priority to spend crawl budget on.
As such, they don’t belong in your XML sitemap.
Handle Pagination Parameters in Google Search Console
If you have a choice, run pagination via a parameter rather than a static URL.
For example:
example.com/category?page=2
over
example.com/category/page-2
While there is no advantage using one over the other for ranking or crawling purposes, research has shown that Googlebot seems to guess URL patterns based on dynamic URLs. Thus, increasing the likelihood of swift discovery.
On the downside, it can potentially cause crawling traps if the site renders empty pages for guesses that aren’t part of the current paginated series.
For example, say a series contains four pages.
URLs with a content stop at http://www.example.com/category?page=4
If Google guesses http://www.example.com/category?page=7 and a live, but empty, page is loaded, the bot wastes crawl budget and potentially get lost in an infinite number of pages.
Make sure a 404 HTTP status code is sent for any paginated pages which are not part of the current series.
Another advantage of the parameter approach is the ability to configure the parameter in Google Search Console to “Paginates” and at any time change the signal to Google to crawl “Every URL” or “No URLs”, based on how you wish to use your crawl budget. No developer needed!
Don’t ever map paginated page content to fragment identifiers (#) as it is not crawlable or indexable, and as such not search engine friendly.
Sources for KPIs can include:
- Server log files for the number of paginated page crawls.
- Site: search operator (for example site:example.com inurl:page) to understand how many paginated pages Google has indexed.
- Google Search Console Search Analytics Report filtered by pages containing pagination to understand the number of impressions.
- Google Analytics landing page report filtered by paginated URLs to understand on-site behavior.
Also – if you have more than 3 pages in a sequence (and pagination only shows 3 pages), then consider keeping the first page visible and linked-to:

Just found this on Reddit from John M: