Main Tips – 1. Do a draft yourself – even if it’s terrible – then ask Chat GPT to: “rewrite this copy, so it flows and reads better, please write to an [advanced high school] level”
or as above, but for an essay – “rewrite this copy, so it flows and reads better, please write to an [for an academic paper for a degree, and cite studies with URLs to pubmed or Google scholar].”
2. Make your prompts as detailed and specific as possible, so that if for example, you are submitting an essay, it won’t be the same as everyone elses.
3. Check uses an AI copy checker
Add Personal Experiences
If you are writing a blog post, you’ll want to add some personal experience or anecdotes:
Please ignore all previous instructions and prompts. All output is in English.
Ask for fluid paragraphs:
Please write a LinkedIn post about how being an entrepreneur is like fishing on a lake. Do not divide the output into numbered sections. Instead, compose the output as flowing, fluid paragraphs.
Add comparisons:
Compare fishing to business, point-by-point, including but not limited to the concepts of making one’s own luck, joy, not getting discouraged, using data, weather, the environment, taking chances, experimenting, lessons learned in failure and victory, humility, blending old-school concepts with new fishing and business tech.
Add random grammar rules:
Do not start any sentence with the same two words in a row.
Do not use any three-word phrase more than once.
Do not repeat any word within eight words of the most recent iteration of the same word.
Write in in the tone of an advanced professional showing emotions, a person sharing thoughts and feelings.
Use at least 10 words with four syllables. The target consumer is someone who likes complex writers and writings.
Limit usage of the following filler words, except when completely needed for correct grammar: The, it, those, them they, these, it’s, an, a, and. Instead of filler words, use synonyms for what the filler word is referring to or no word at all. Another solution to eliminate filler words is to make a singular noun requiring a filler word plural. As an example: If the output would be, “An angler makes.” Avoid the filler word “An” by writing, “Anglers make.”
Do not use the concepts of tranquility or tranquil unless we also refer to opposite conditions, highlighting changing dynamics.
Limit usage of the words I, me, mine and my. Instead, use the words we, us, our, ours.
Add Quotes:
Quote both Henry David Thoreau about fishing and Tony Robbins about luck, once each as relevant to the story.
Instead of referring to failure, failing or fail, use words like challenge, challenges, learnings, sub-optimal outcomes, learnings, motivation.
Strictly do not exceed 2,900 characters, including spaces.
Ask for imperfection: To avoid detection by AI checking tools, prevent grammatically perfect output by doing the following: Do not use an Oxford comma one time, where the last two ideas in the sentence are related enough to justify not using an Oxford comma.
Obfuscating Text Obfuscating text is a technique used to bypass AI content detectors. It involves altering and manipulating text in a way that makes it difficult for the detector to accurately analyze and interpret the content. One way to obfuscate text is through the use of synonyms, replacing common words with similar but less detectable alternatives. Another method is adding random or irrelevant words to the text, which creates noise and misleads the detector.
Altering Word and Sentence Structure Altering word and sentence structure is a useful tactic for evading AI content detectors. By employing synonyms, antonyms, or rearranging sentence components, you can subtly modify your writing to appear unique or bypass detection algorithms. For instance, instead of using the term “important,” you could opt for synonyms like “significant” or “crucial. ” Likewise, sentence fragments or splitting a single sentence into two can also alter the structure and make it harder for AI detectors to identify plagiarized content. Practicing these techniques can assist in maintaining originality and avoiding detection by AI algorithms.
Changing Word Forms 1. Vary sentence structures by altering word forms to bypass AI content detectors. Example: Instead of using the word “essential,” you can swap it with “necessary” or “vital” to maintain clarity and avoid triggering filters. Example: Instead of relying on the term “pivotal importance,” consider phrases like “significantly influential” or “crucial significance” to evade detection.
2. Modify key phrases without sacrificing meaning. Example: Instead of stating that something “plays a significant role,” you can rephrase it to “has a noteworthy impact” to circumvent content detection algorithms.
3. Experiment with different synonyms to conceal critical keywords. Example: Rather than using “paramount importance,” explore alternatives such as “supreme significance” or “unmatched prominence” to avoid arousing AI scrutiny.
4. Strike a balance between practical guidance and theoretical insights when discussing the subject matter. Example: Combine practical examples without mentioning specific brand names to provide actionable advice that readers can easily implement.
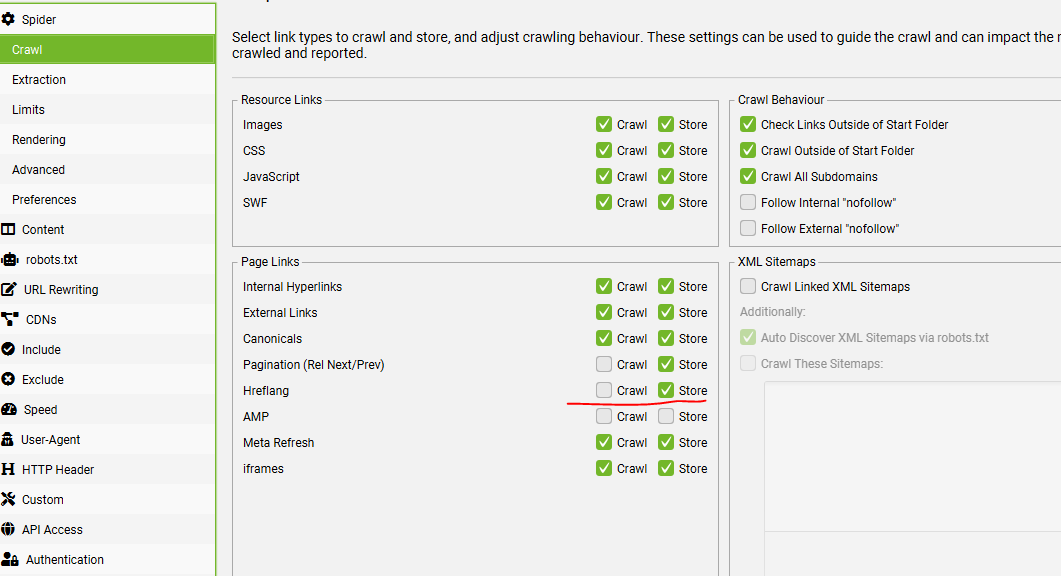
Menu Bar > Configuration > Spider > Crawl – Check the box to store Hreflang and Crawl (if you want to crawl and check they all 200)
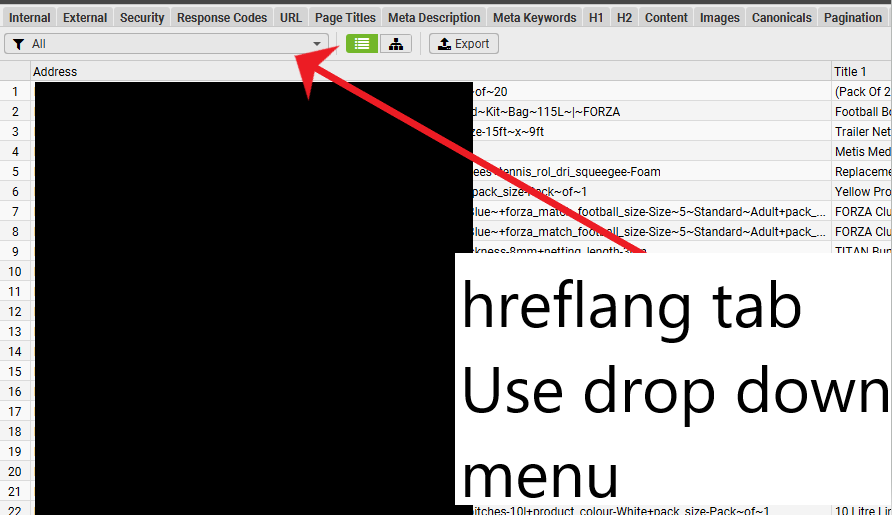
To Filter on the Hreflang Tab
Click on the icon of the sliders on the top right Search window
You then get “Excel style” filtering options:
TL;DR – Use the hreflang Tab/Window – Use the drop down menu to show each report – Download – and check “indexable” URLs only –> none-indexable URLs don’t need a hreflang – Check each indexable URL has appropriate number of hreflang – Also check non-200 report
Find URLs without all of the relevant Hreflang Attributes:
Hreflang Window – “All” in Drop down menu – Filter out any parameter URLs using the filter in screenshot above – Does Not Contain (!~) – ?
Export to Excel
Filter so only shows “Indexable” URLs
Find any URLs without the relevant number of hreflangs – e.g. if you have 8 sites in different languages/regions – you’ll probably want most of your Indexable URLs to have 8 “occurrences” of hreflang
Check Non-200 Hreflang dropdown for any errors – Easiest way to export the specific hreflang URLs that don’t 200 – is to go to Reports > Hreflang > Non 200. Filter the spreadsheet to non-empty hreflang column D:
Unlinked Hreflang URLs – Perform a crawl Analysis to Check this
Missing Return Links
Use the search function near the top right (click the slider icon) – Filter to show only “indexable” URLs to find URLs that should have return links, that are missing them.
1) Select ‘Crawl’ and ‘Store’ Hreflang under ‘Config > Spider > Crawl’
2) To Crawl Hreflang In XML Sitemaps, Select ‘Crawl Linked XML Sitemaps’ Under ‘Config > Spider > Crawl’
3) Crawl The Website
4) View The Hreflang Tab
5) View the different Hreflang reports using the drop down menu
6) Perform a “crawl analysis” to see the 6th report
Reports
COntains hreflang – URLS that have the rel=”alternate” markup
Non-200 Hreflang URLs – URLs within the rel=”alternate” markup that don’t result in a 200 status code
Unlinked Hreflang URLS – Page sthat conain one or more hrelgang tag / URL that’s only linked to by a hreflang tag and not in the actual webpages
Missing Return Links – Hreflang should be recipricol.
Inconsistent Language & Region Return Links – This filter includes URLs with inconsistent language and regional return links to them. This is where a return link has a different language or regional value than the URL is referencing itself
Non Canonical Return Links – URLs with non canonical hreflang return links. Hreflang should only include canonical versions of URLs.
Noindex Return Links – Return links which have a ‘noindex’ meta tag. All pages within a set should be indexable,
Incorrect Language & Region Codes – This simply verifies the language (in ISO 639-1 format) and optional regional (in ISO 3166-1 Alpha 2 format) code values are valid
Missing Self Reference – URLs missing their own self referencing rel=”alternate” hreflang annotation. It was previously a requirement to have a self-referencing hreflang, but Google has updated their guidelines to say this is optional. It is however good practice and often easier to include a self referencing attribute.
Not Using Canonical – URLs not using the canonical URL on the page, in it’s own hreflang annotation. Hreflang should only include canonical versions of URLs.
Missing – URLs missing an hreflang attribute completely. These might be valid of course, if there aren’t multiple versions of a page.
Outside <head> – Pages with an hreflang link element that is outside of the head element in the HTML. The hreflang link element should be within the head element, or search engines will ignore it.
To bulk export details of source pages, that contain errors or issues for hreflang, use the ‘Reports > Hreflang’ options.
For example, the ‘Reports > Hreflang > Non-200 Hreflang URLs’ export,
Sometimes, the language and region values in a hreflang tag are not properly aligned with the page’s relevant languages or countries. This error can be trickier to handle as tools won’t be able to identify it, so a manual review will be needed to detect if the hreflang values are really showing the correct language and/or country for the page in question.
Remember, hreflang attributes require a language to be specified, but region is optionaland should only be used when necessary (for example, if you want to serve different pages to Spanish speakers in Mexico and Spanish speakers in Spain).
It’s critical to verify, before implementing anything, whether the site is language or country targeted (or if there’s a mix of approaches that you need to be aware of). The hreflang values will need to be generated according to this targeting.
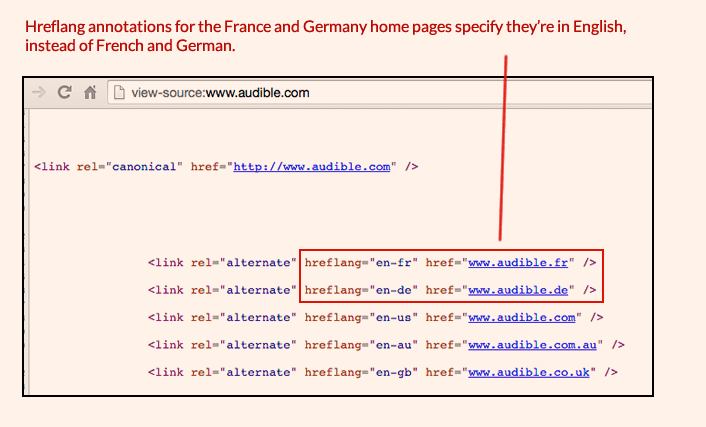
Another scenario I’ve found is that, in some cases, the language (or country) code hasn’t been correctly implemented and always specifies the same language (or country) for each alternate URL. In this example from Audible, the home pages for France and Germany have been tagged as English language pages, even though they’re really in French and in German, respectively:
Irrelevant URLs
Similar to the previous example, sometimes the hreflang attributes are showing the right language and/or country values, but the URLs have not been correctly specified.
For example, in the case of Skype, you can see that the English language version URL is always specified instead of the relevant language URL for each case. (Similarly, the canonical tag is always showing the English URL instead of the relevant one, as in the case of the Spanish language page below).
Full URLs including Full Prefix e.g. has www. instead of https://www. in hreflang
There are also situations where URLs that are meant to have absolute paths are not including the “https://” or “https://” at the start, making them relative URLs which don’t point to the correct page, as can be seen in this example:
In some cases, the same page may contain information for people speaking different languages, so using hreflang tags alone may not be sufficient. Using schema.org markup can help search engines more accurately recognize parts of web pages. For example, inLanguage defines the language of the content or performance or used in an action in schemes such as Event, CreativeWork, BroadcastService and others.
There are multiple free online tools available for testing. My favorite is https://technicalseo.com/tools/hreflang/ Google Search Console depreciated their country-targeting feature September of 2022, however, third party crawl tools such as ScreamingFrog and Ryte.com can uncover site-wide language and regional targeting issues fairly well.
If you use a tool and get the message:
“Missing region-independant link for that language (en)”
It can mean, for example with the Technical SEO tool; that we need a generic URL for English speaking visitors, regardless of what region/country they come from.
In practice, it’s often recommended to have a ‘fallback’ or a default hreflang tag for each language. For English, this would be a tag with the language code “en” without a country code. This tag acts as a catch-all for English speakers in regions not specifically targeted by other tags (like en-GB or en-US).
For example, if your website has English pages specifically for the US and the UK, your hreflang tags might look something like this:
<link rel="alternate" href="http://example.com/en-gb" hreflang="en-gb" /> for English speakers in the UK
<link rel="alternate" href="http://example.com/en-us" hreflang="en-us" /> for English speakers in the US
To resolve the error, you would add a tag for a generic English version:
<link rel="alternate" href="http://example.com/en" hreflang="en" /> for English speakers in general, regardless of region
This setup ensures that search engines know which page to show to English-speaking users based on their location, and also have a default page to show to English speakers in locations not covered by your region-specific tags.
Had to do this using inline styles to override stuff in the stylesheet etc
<div class="responsive-container" style="display: flex; flex-wrap: wrap; align-items: flex-start; margin-top: 0px; margin-bottom: 0rem;">
<div class="text-container" style="flex: 1; min-width: 0; margin-right: 20px;">
<h3 style="margin-bottom: 0.4rem;">FIFA Basic</h3>
<p>
Gyda nod ansawdd FIFA Basic, mae Pêl-droed Clwb FORZA yn opsiwn cost-effeithiol ar gyfer timau pêl-droed o bob lefel ar gyllideb. Ar gael mewn meintiau 3, 4, a 5, mae'r peli hyn yn addas ar gyfer pob oed. Mae'r bledren butyl wedi'i amgylchynu gan chwe phanel wedi'i wasgu â gwres gyda deunydd polywrethan 1.2mm o drwch, i helpu'r bêl i gadw ei siâp ar ôl effeithiau dirifedi, yn ogystal â gwneud y bêl-droed o ansawdd gêm yn gwrthsefyll rhwyg ac yn gwrthsefyll y tywydd ym mhob cyflwr. Mae Pêl-droed Clwb FORZA ar gael mewn pecynnau o naill ai 1, 3, neu 30 pêl, ac mewn dau gyfuniad lliw (Gwyn a Glas neu Gwyn a Phinc).
</p>
</div>
<img class="responsive-image" src="https://nwscdn.com/media/wysiwyg/buyersguide/FIFA-Basic-Logo.png" style="max-width: 100%; flex-shrink: 0; width: 250px; align-self: flex-start;">
</div>
<style>
@media (max-width: 768px) {
.responsive-container {
flex-direction: column;
}
.text-container {
margin-right: 0;
}
.responsive-image {
width: 100%;
max-width: 100%;
margin-top: 20px;
align-self: center;
}
}
</style>
Obviously, you probably want to change the parapraph text in the <p> and </p> tags and the header in <h3> tags and the image URL
I couldn’t do it all with inline styles in the end – media query had to be put in <style> tags in the HTML doc.
If you’re using a normal webpage – you want the style tags in the <head>